Ah, Spark ! Le couteau suisse de la donnée, n'est-ce pas ? On peut tout faire avec, ou presque. Et parmi toutes ces fonctionnalités, il y en a une qui nous sauve souvent la mise : l'inférence de schéma. Imaginez la scène...
Vous rentrez du marché, les bras chargés de légumes frais, sans la liste de courses. Vous vous souvenez plus ou moins de ce que vous vouliez acheter, et vous vous dites : "Pas grave, je vais improviser !". C'est exactement ça, l'inférence de schéma. Spark se dit : "OK, il y a un fichier CSV là. Pas de problème, je vais essayer de deviner ce qu'il contient !" C’est un peu voyant, non ?
Le principe de l'inférence de schéma : Sherlock Holmes version Data
En gros, Spark, comme un Sherlock Holmes de la donnée, examine votre fichier (CSV, JSON, Parquet, peu importe) et essaye de deviner la structure des données. Il regarde chaque colonne et se demande : "Est-ce que ça ressemble à un nombre ? À une date ? À du texte ?".
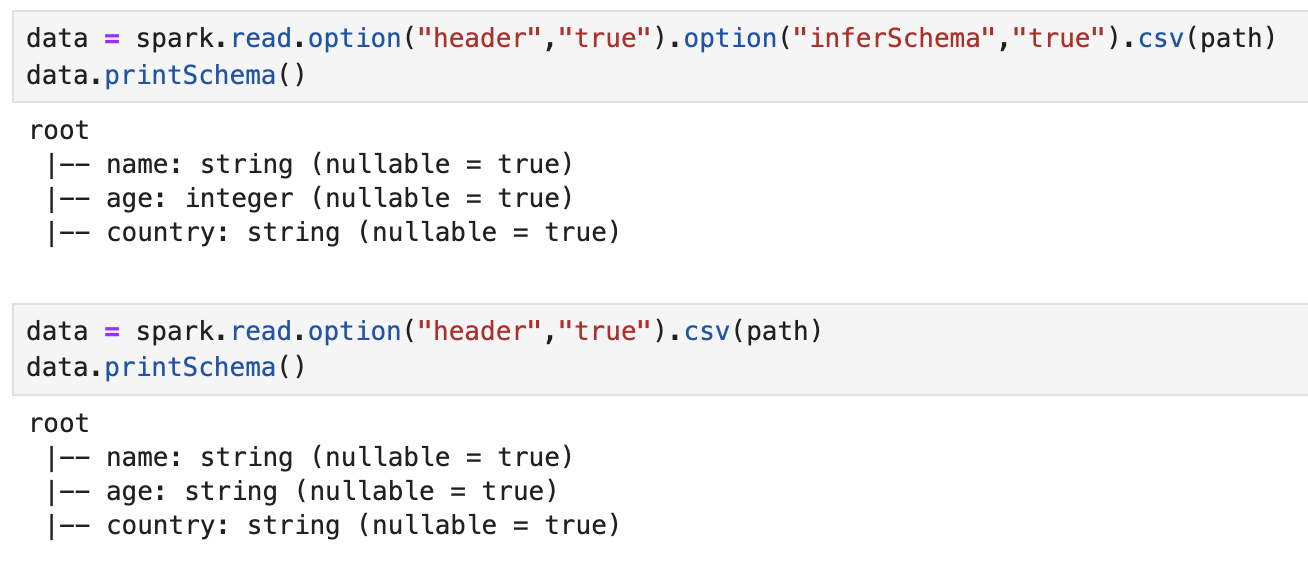
Disons que vous avez une colonne avec des chiffres comme "1", "2", "3". Spark se dit : "Bingo ! C'est probablement un entier (Integer)". S'il voit des nombres avec des décimales, comme "3.14", "2.71", il se dit : "Ah, un double (Double) !" Et s'il rencontre du texte, comme "Bonjour", "Au revoir", "Spark est génial", alors il conclut : "C'est une chaîne de caractères (String)". Simple, non ?
Les avantages : la flemme assumée et l'efficacité
Pourquoi se casser la tête à définir chaque colonne manuellement quand Spark peut le faire pour nous ? Soyons honnêtes, la plupart du temps, on est un peu flemmards. On préfère que la machine fasse le boulot à notre place. Et c'est là que l'inférence de schéma brille de mille feux.

Plus concrètement, ça veut dire :
- Gain de temps précieux : Plus besoin de passer des heures à analyser la structure du fichier. Spark le fait en quelques secondes.
- Moins d'erreurs : Définir un schéma à la main, c'est le risque d'oublier une colonne ou de se tromper de type. L'inférence de schéma minimise ce risque.
- Flexibilité accrue : Parfait pour les fichiers de données dont la structure est susceptible de changer. Spark s'adapte automatiquement.
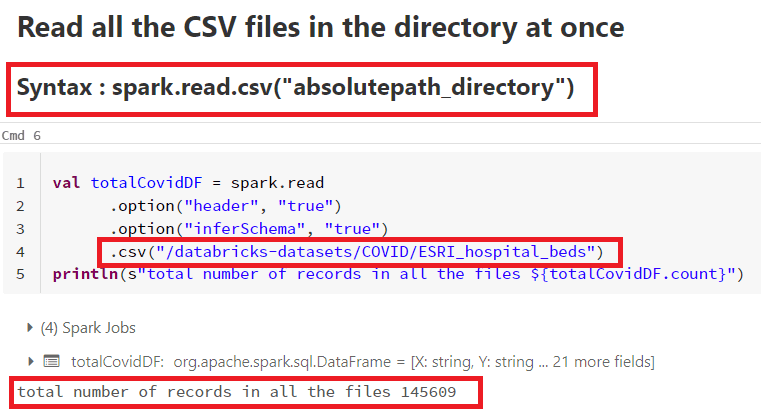
Un exemple concret ? Imaginez que vous recevez tous les jours un fichier CSV avec les ventes de votre entreprise. Chaque jour, le fichier peut avoir une colonne en plus ou en moins. Avec l'inférence de schéma, pas de panique ! Spark va détecter automatiquement les changements et adapter le schéma en conséquence. C'est magique !
Les pièges à éviter : quand Sherlock Holmes se trompe...
Attention, l'inférence de schéma n'est pas infaillible. Comme Sherlock Holmes, elle peut se tromper, surtout si les données sont un peu bizarres. Imaginez une colonne avec des dates au format américain (MM/JJ/AAAA). Spark, s'il est configuré en format européen (JJ/MM/AAAA), risque de les interpréter comme des nombres, et là, c'est le drame !

Autre cas de figure : une colonne avec des nombres, mais avec des valeurs manquantes représentées par des chaînes de caractères comme "N/A" ou "Inconnu". Spark risque de considérer toute la colonne comme une chaîne de caractères. Et là, c'est la catastrophe si vous voulez faire des calculs !
Il faut donc rester vigilant et vérifier que Spark a bien deviné le schéma. On peut utiliser la méthode printSchema() pour afficher le schéma inféré et s'assurer qu'il est correct.

Et si on constate une erreur ? Pas de panique ! On peut toujours forcer le schéma en le définissant manuellement. C'est un peu plus de travail, mais au moins, on est sûr du résultat. C'est comme relire sa copie avant de la rendre, toujours une bonne idée !
Quelques astuces pour une inférence de schéma réussie
Voici quelques conseils pour optimiser l'inférence de schéma :
- Fournir un échantillon représentatif : Plus Spark a de données à analyser, plus il a de chances de deviner correctement le schéma. Si votre fichier est énorme, vous pouvez lui fournir un échantillon (sample) des premières lignes.
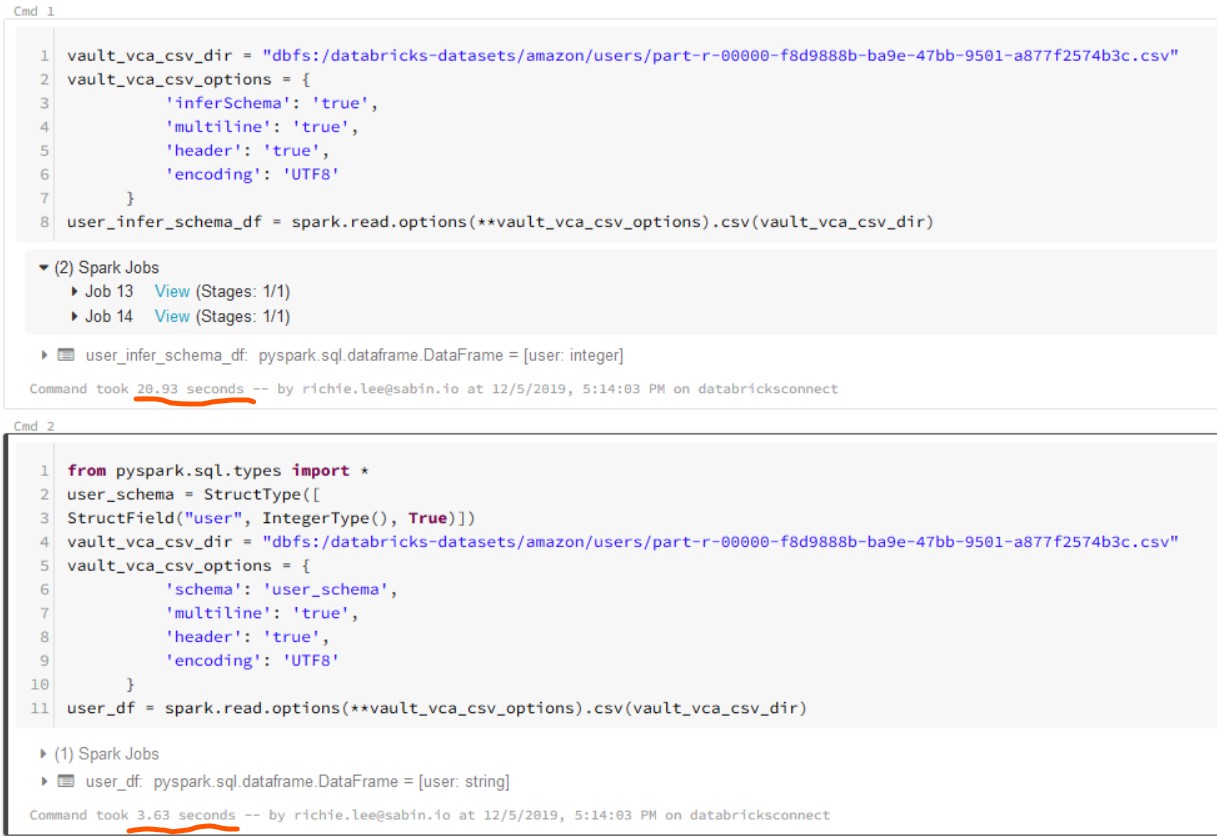
- Spécifier les options de lecture : Indiquez à Spark le format de date, le séparateur de colonnes, le caractère d'échappement, etc. Ça l'aidera à mieux comprendre les données. C'est comme donner une loupe à Sherlock Holmes.
- Vérifier le schéma inféré : Utilisez
printSchema()pour afficher le schéma et vous assurer qu'il est correct. Mieux vaut prévenir que guérir ! - Définir un schéma explicite en cas de doute : Si vous avez des données complexes ou ambigües, n'hésitez pas à définir le schéma manuellement. C'est plus sûr.
En résumé, l'inférence de schéma est un outil puissant et pratique, mais il faut l'utiliser avec prudence. C'est un peu comme un pilote automatique : c'est génial pour les longs trajets, mais il faut quand même garder les mains sur le volant !
L'inférence de schéma, votre allié au quotidien
Alors, la prochaine fois que vous aurez un fichier de données à lire avec Spark, pensez à l'inférence de schéma. Elle vous fera gagner du temps, vous évitera des erreurs et vous permettra de vous concentrer sur l'essentiel : l'analyse des données et la prise de décisions éclairées. Et puis, avouons-le, c'est quand même plus fun que de définir un schéma à la main, non ?
Imaginez maintenant pouvoir consacrer tout ce temps gagné à... que sais-je, préparer une bonne tarte aux pommes avec tous ces légumes frais ramenés du marché ! C'est ça, la magie de Spark et de l'inférence de schéma : vous libérer du temps pour les choses qui comptent vraiment. Alors, à vos données, et bonne dégustation !
Et souvenez-vous : Un bon data scientist est un data scientist paresseux qui sait utiliser les bons outils ! 😉