Salut l'ami(e) ! Alors, on se plonge dans le monde merveilleux (oui, oui, merveilleux!) de la table de la distribution t ? Ne panique pas, c'est moins effrayant qu'un contrôle surprise de maths lundi matin. Promis ! Imagine-toi qu'on boit un café (ou un thé, selon tes préférences) et qu'on papote de statistiques comme si c'était la dernière série Netflix à la mode. Let's go!
C'est quoi, cette table t, au juste ?
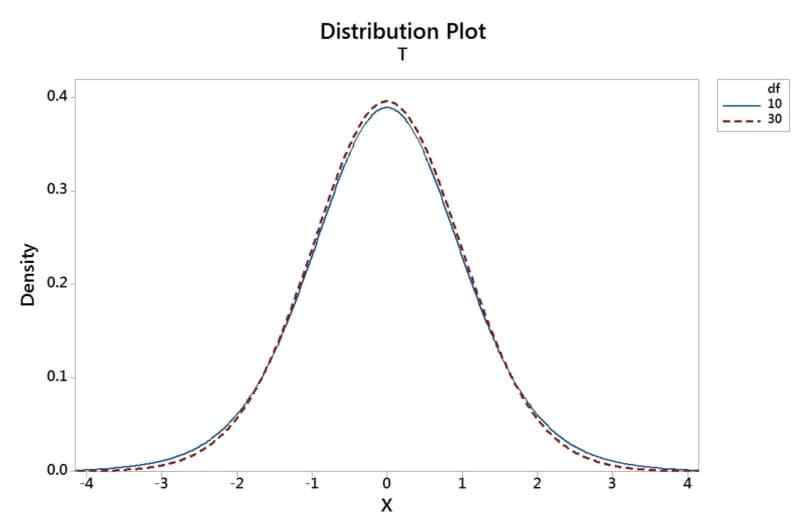
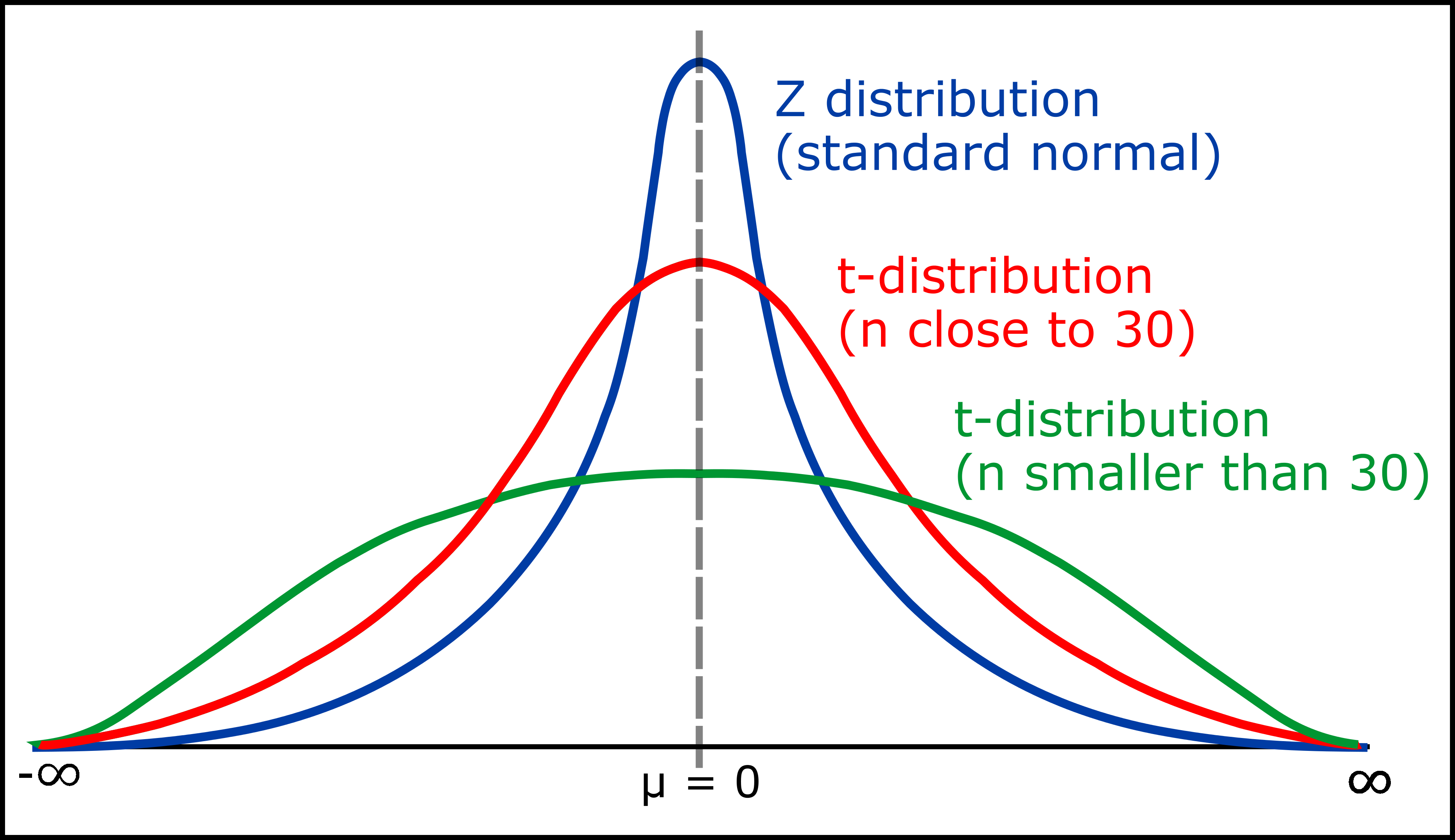
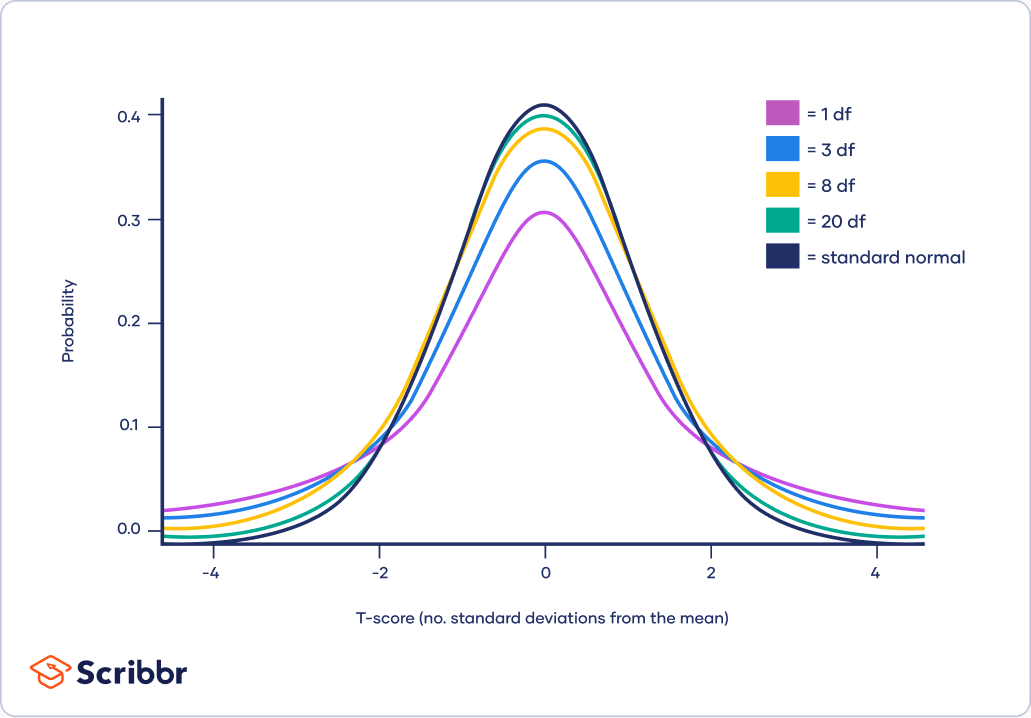
En gros, la table de la distribution t, c'est un peu comme la carte au trésor pour les statisticiens. Elle nous aide à faire des prédictions et des estimations sur des populations quand on n'a pas toutes les infos. Souvent, on travaille avec des échantillons plus petits, et c'est là que la table t entre en jeu. La distribution t est plus adaptée que la distribution normale (la fameuse courbe en cloche !) quand la taille de l'échantillon est réduite. Pense à elle comme à la cousine cool et un peu plus "street smart" de la distribution normale.
La distribution t, inventée par William Sealy Gosset (qui écrivait sous le pseudonyme de "Student" pour éviter des ennuis avec son employeur, la brasserie Guinness! Ah, ces statisticiens rebelles!), est en réalité une famille de distributions. Chaque distribution est définie par ses degrés de liberté (degrees of freedom en anglais). Et c'est là que la table devient utile !
Les degrés de liberté, kesako ?
Les degrés de liberté, c'est un concept qui peut paraître un peu abstrait au début, mais c'est en fait assez simple. Imagine que tu as 5 amis et que tu veux leur distribuer 5 bonbons. Le premier ami peut choisir n'importe lequel des 5 bonbons. Le deuxième ami peut choisir parmi les 4 restants, et ainsi de suite. Mais le dernier ami n'a plus le choix: il doit prendre le dernier bonbon qui reste. Il n'a donc pas de liberté de choix. Dans ce cas, on a 4 degrés de liberté (5 amis - 1 contrainte = 4).
En statistiques, les degrés de liberté sont souvent liés à la taille de l'échantillon. Généralement, pour un test t, les degrés de liberté sont égaux à la taille de l'échantillon moins 1 (n-1). Pourquoi ? Parce qu'on utilise l'échantillon pour estimer une moyenne, et cette estimation impose une contrainte sur les données.

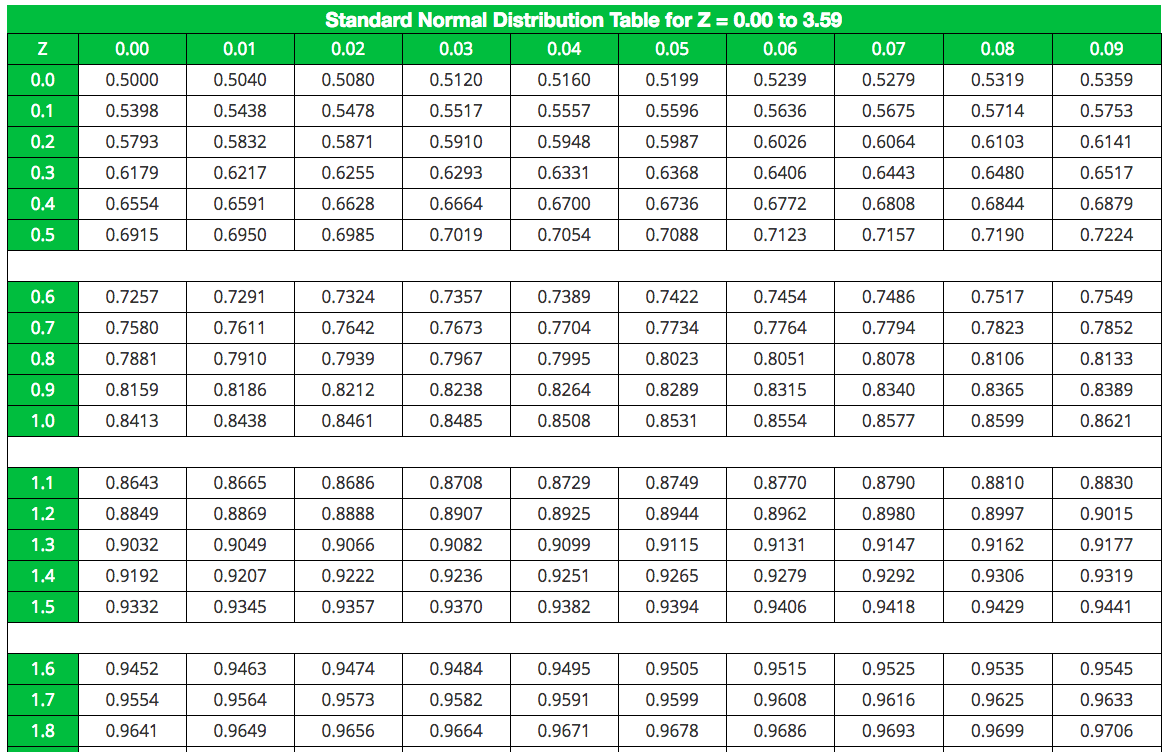
Comment lire cette fameuse table ?
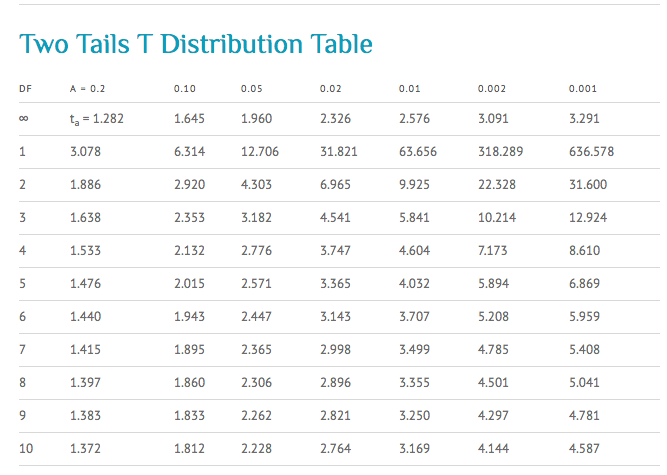
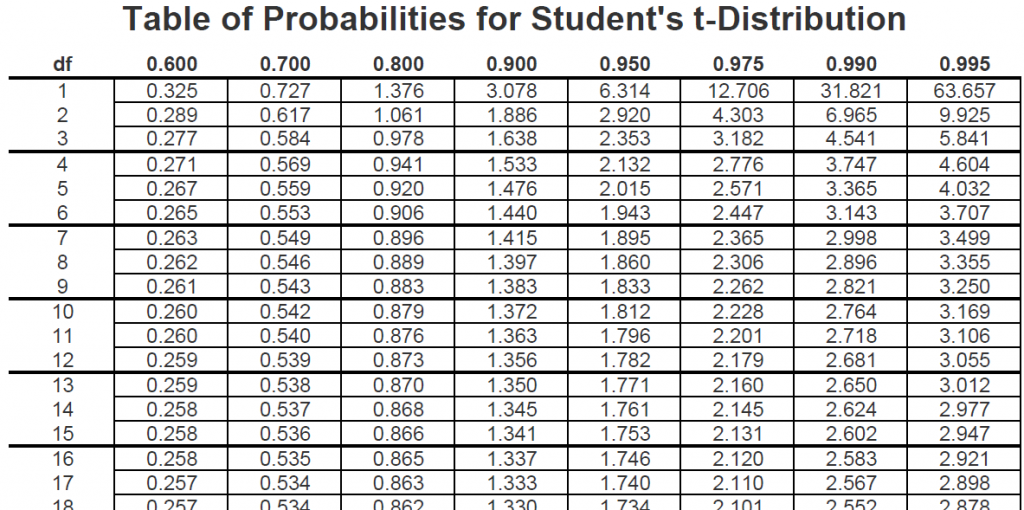
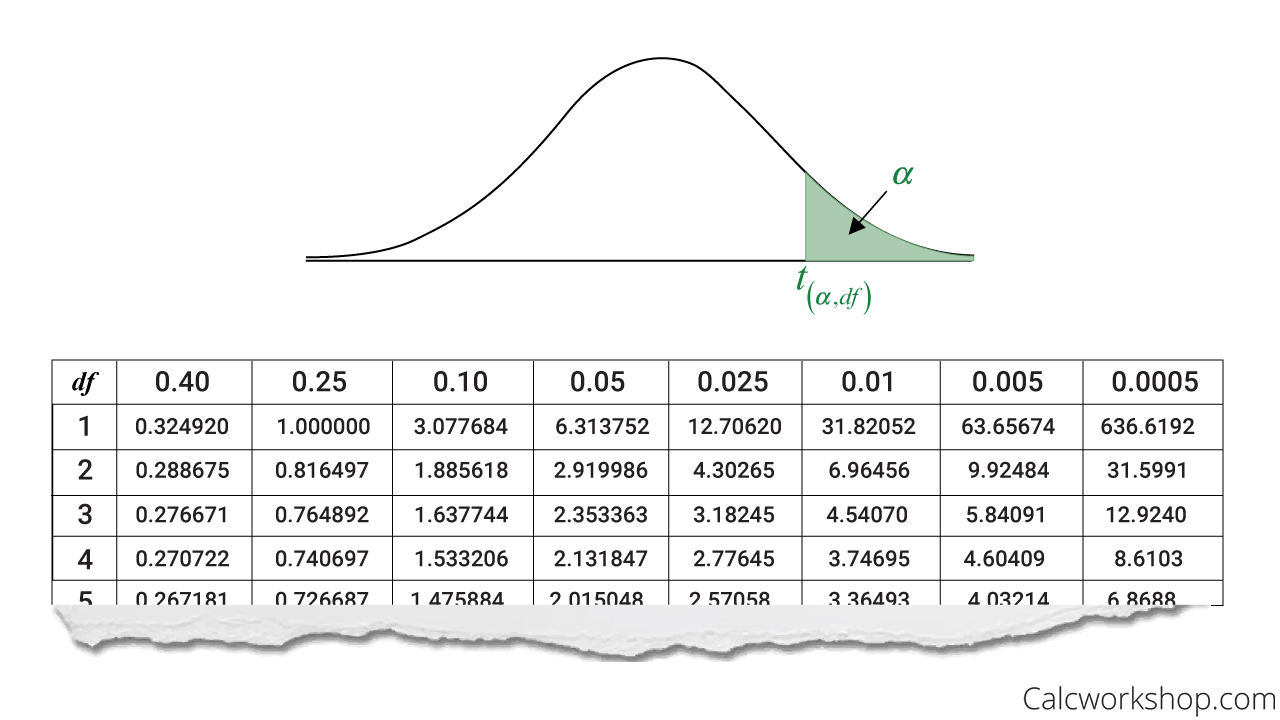
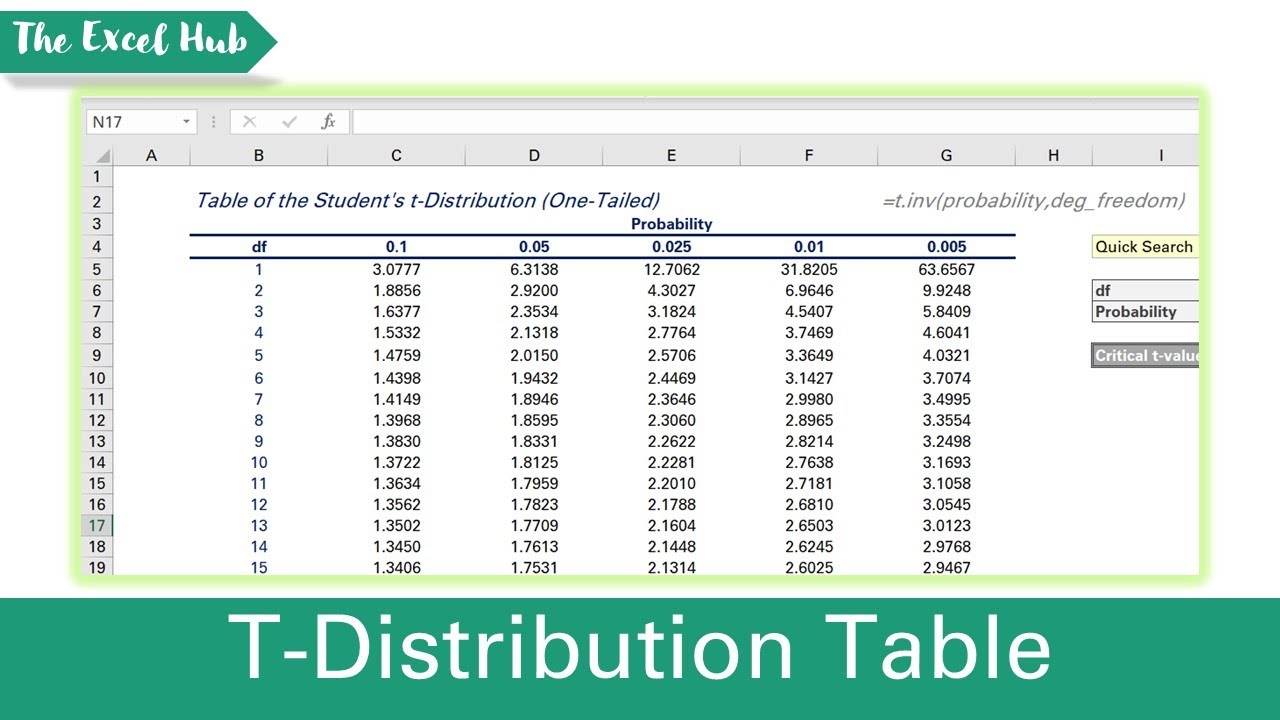
C'est le moment de sortir ta loupe (bon, peut-être pas vraiment, mais tu vois l'idée!). Une table de distribution t ressemble souvent à un tableau avec des lignes et des colonnes.
Les lignes représentent les degrés de liberté (df). Tu les trouveras généralement sur la gauche de la table. Cherche la ligne correspondant à tes degrés de liberté (n-1). Par exemple, si tu as un échantillon de 30 observations, tu auras 29 degrés de liberté.
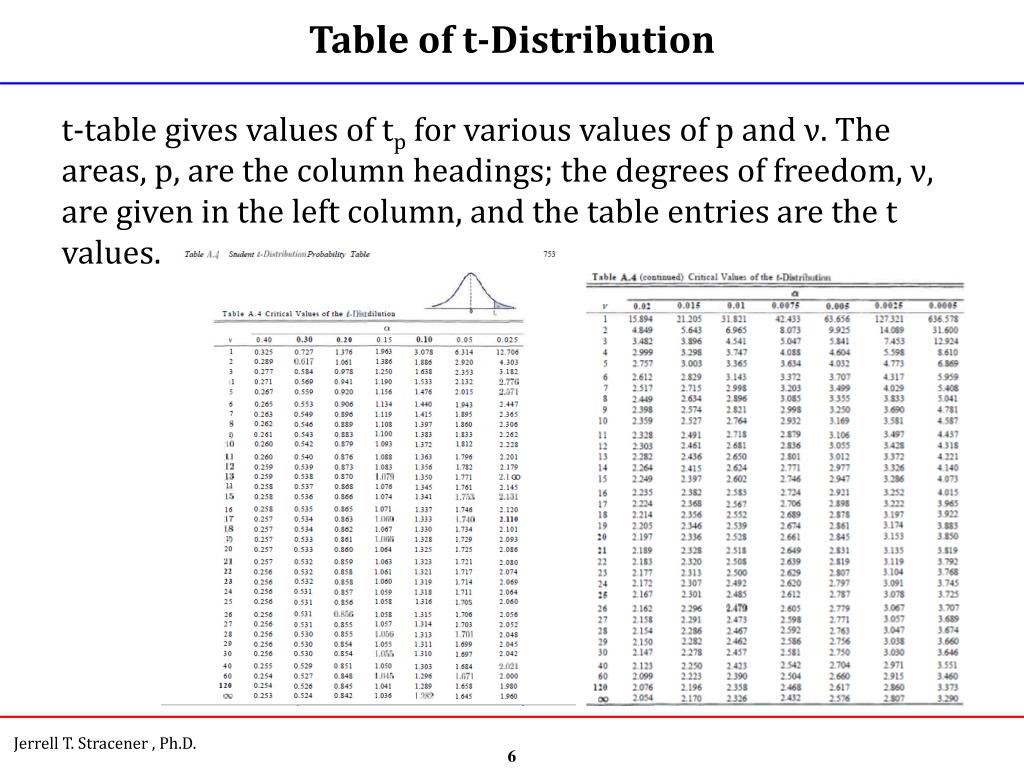
Les colonnes représentent les niveaux de signification (alpha, souvent noté α) ou les niveaux de confiance. Le niveau de signification, c'est la probabilité de rejeter l'hypothèse nulle alors qu'elle est vraie (aussi appelé erreur de type I). Un niveau de signification courant est 0.05 (5%). Le niveau de confiance, c'est la probabilité que l'intervalle de confiance contienne la vraie valeur du paramètre. Un niveau de confiance courant est 95% (1-alpha). Tu trouveras ces valeurs en haut de la table. Cherche la colonne correspondant à ton niveau de signification (par exemple, 0.05) ou à ton niveau de confiance (par exemple, 95%).
L'intersection de la ligne correspondant à tes degrés de liberté et de la colonne correspondant à ton niveau de signification te donne la valeur critique t. C'est cette valeur que tu vas comparer à ta statistique de test pour déterminer si tu peux rejeter ou non l'hypothèse nulle.
Petite astuce : Certaines tables sont "unilatérales" (one-tailed en anglais) et d'autres sont "bilatérales" (two-tailed). Assure-toi d'utiliser la bonne table en fonction de ton test d'hypothèse! Un test unilatéral regarde si la moyenne est significativement plus grande ou plus petite qu'une certaine valeur. Un test bilatéral regarde si la moyenne est significativement différente (plus grande ou plus petite) d'une certaine valeur.
Un exemple concret pour que tout soit clair !
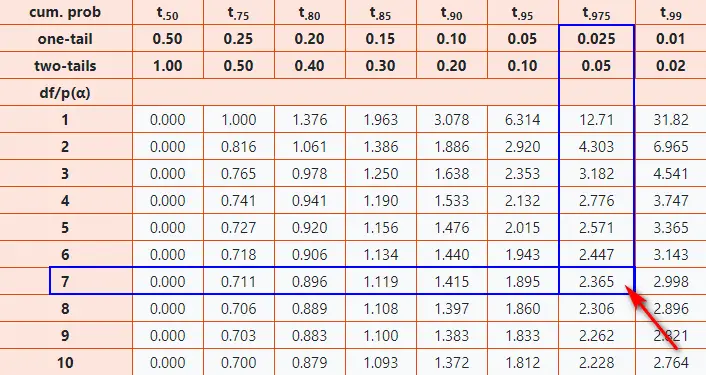
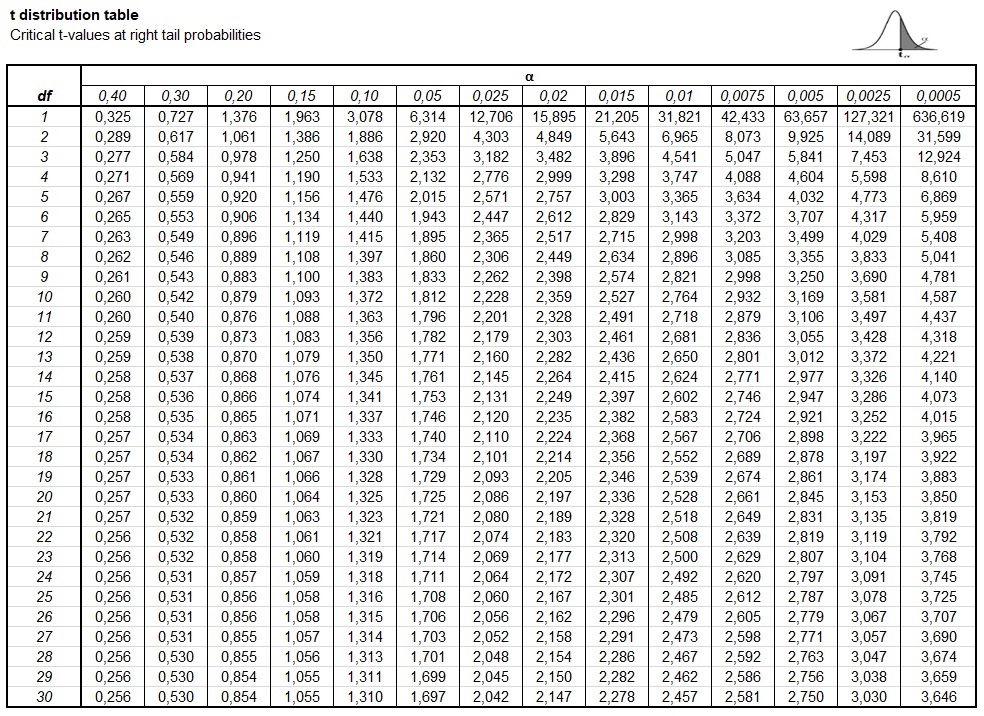
Imaginons que tu veux tester si la taille moyenne des étudiants de ton université est différente de 175 cm. Tu prélèves un échantillon de 25 étudiants et tu obtiens une moyenne de 178 cm avec un écart-type de 8 cm. Tu effectues un test t et tu obtiens une statistique de test de 2.34.
Tes degrés de liberté sont de 25 - 1 = 24. Tu choisis un niveau de signification de 0.05 (5%). Comme tu veux tester si la taille moyenne est différente de 175 cm (pas seulement plus grande ou plus petite), tu utilises un test bilatéral.

Tu regardes dans ta table de distribution t, à la ligne correspondant à 24 degrés de liberté et à la colonne correspondant à un niveau de signification de 0.05 (bilatéral). Tu trouves une valeur critique de 2.064.
Comme ta statistique de test (2.34) est supérieure à la valeur critique (2.064), tu rejettes l'hypothèse nulle. Cela signifie que tu as suffisamment de preuves pour affirmer que la taille moyenne des étudiants de ton université est significativement différente de 175 cm.
Quelques petites remarques importantes
- Plus les degrés de liberté sont élevés, plus la distribution t se rapproche de la distribution normale. Avec un très grand échantillon (disons, plus de 120 observations), tu peux utiliser la distribution normale à la place de la distribution t. Mais bon, autant utiliser la table t, ça ne coûte rien!
- Attention à bien choisir ton niveau de signification ! Un niveau de signification trop élevé augmente le risque de rejeter l'hypothèse nulle alors qu'elle est vraie. Un niveau de signification trop faible diminue le risque de rejeter l'hypothèse nulle alors qu'elle est fausse. C'est un équilibre délicat à trouver !
- Les logiciels statistiques (R, Python, SPSS, etc.) font tous ces calculs automatiquement ! Donc, tu n'as pas forcément besoin d'imprimer une table t et de la trimbaler partout. Mais il est toujours bon de comprendre ce qu'il se passe "sous le capot".
En conclusion (avec le sourire !)
Voilà ! On a fait le tour (ou presque!) de la table de distribution t. Ce n'est pas si compliqué, hein ? Avec un peu de pratique, tu vas devenir un(e) pro de l'interprétation de cette table. Et même si les statistiques peuvent parfois te donner le tournis, n'oublie pas que c'est un outil puissant pour comprendre le monde qui nous entoure. Alors, respire un grand coup, prends un autre café (ou un autre thé!), et continue à explorer le fascinant univers des statistiques. Tu vas voir, c'est passionnant (si, si, je t'assure!). Et souviens-toi, même les plus grands statisticiens ont commencé quelque part. Alors, n'abandonne jamais tes rêves (statistiques ou autres !). À la prochaine pour de nouvelles aventures statistiques ! 😉